prob-begin

main함수에선 16바이트를 입력받고

initcpu함수로 값을 복사한다.

그리고 복사한 값을 runcpu함수로 전달한다. runcpu함수를 보면 전형적인 vm문제이다. stub배열에 있는 값을 opcode로 사용하고 opcode에 따라서 우리가 입력한 값에다가 덧셈, 뺄셈, xor, or등 다양한 연산을 수행한다.
일단 여기까지만 봤을때 IDA가 잘못 해석한게 있다. 포인터 연산을 할때 인덱스에다가 4를 곱하니까 이 함수에 전달되는 인자는 __int64가 아니라 그냥 int타입이다. 그리고 runcpu함수에 전달되는건 포인터니까 runcpu의 매개변수인 a1변수도 __int64 a1에서 int a1로 바꿔준다.


이렇게 잘못 해석된 변수들의 타입을 바꿔주면 우리가 보기 편하게 표시가 된다. vm에서 이것저것 연산을 수행한 후에 함수가 return을 하면

최종적으로는 연산한 결과 배열의 7번째 인덱스가 0이어야 한다는 것을 알 수 있다.
이러한 vm문제를 푸는 전략은 포너블의 경우에는 vm에서 취약점을 찾고 opcode를 직접 짜서 익스해야 되기 때문에 각 기능들을 분석해서 원하는 기능의 opcode를 생성해주는 함수들을 짜고 익스하는게 일반적이다. (물론 나는 귀찮아서 그냥 무지성으로 opcode조합하는데 복잡한거 나오면 함수 만드는게 좋을듯 하다.) 하지만 리버싱의 경우에는 이번에 배웠는데 포너블과 다르게 vm의 연산에 쓰이는 opcode가 주어지니까 python을 이용해서 vm머신이 어떤 연산을 하는지 보여주는 스크립트를 짜준 후에 출력되는 결과물을 분석해서 역산을 짜던 z3를 돌리던 하면 되는거였다.
생각해보면 당연한건데 내가 이렇게 자동화할 생각을 못하고 하나하나 직접 보려고 해서 리버싱 vm문제가 어렵게 느껴졌던것 같다. 이제 알았으니 vm많이 풀어봐야지 :)
vm = [ 0x46, 0x04, 0xCD, 0x04, 0xD4, 0x0A, 0x45, 0x00, 0x04, 0x46,
0x04, 0xAB, 0xBF, 0xD1, 0x30, 0x5A, 0x00, 0x04, 0x46, 0x04,
0xB2, 0x83, 0x9E, 0x51, 0x5A, 0x00, 0x04, 0x46, 0x05, 0xBB,
0x80, 0x7C, 0x4F, 0x5A, 0x01, 0x05, 0x46, 0x05, 0x63, 0x1C,
0x0D, 0x76, 0x55, 0x01, 0x05, 0x46, 0x05, 0x93, 0xC3, 0x31,
0x94, 0x5A, 0x01, 0x05, 0x46, 0x06, 0xFB, 0xB2, 0xB9, 0xE8,
0x55, 0x02, 0x06, 0x46, 0x06, 0x29, 0xD7, 0x71, 0x9A, 0x45,
0x02, 0x06, 0x46, 0x06, 0x75, 0x6D, 0x06, 0x00, 0x5A, 0x02,
0x06, 0x46, 0x07, 0x72, 0xA2, 0x6E, 0x3E, 0x5A, 0x03, 0x07,
0x46, 0x07, 0x74, 0xAC, 0x11, 0xD4, 0x5A, 0x03, 0x07, 0x46,
0x07, 0x43, 0x5C, 0x5E, 0x97, 0x5A, 0x03, 0x07, 0x5A, 0x07,
0x07, 0x50, 0x07, 0x00, 0x50, 0x07, 0x01, 0x50, 0x07, 0x02,
0x50, 0x07, 0x03, 0xCC, 0xDB, 0x26, 0x5A, 0x02, 0xDD, 0x8F,
0x4F, 0x10, 0xD9 ]
idx = 0
while True:
op = vm[idx]
if op == 0x46:
print("REG[%d] = 0x%08X" % (vm[idx+1], int.from_bytes(vm[idx+2:idx+2+4], "little")))
print("REG[%d] &= 0xFFFFFFFF" %(vm[idx + 1]))
idx += 5
elif op == 0x45:
print("REG[%d] += REG[%d]" % (vm[idx+1], vm[idx+2]))
print("REG[%d] &= 0xFFFFFFFF" %(vm[idx+1]))
idx += 2
elif op == 0x55:
print("REG[%d] -= REG[%d]" % (vm[idx+1], vm[idx+2]))
print("REG[%d] &= 0xFFFFFFFF" %(vm[idx+1]))
idx += 2
elif op == 0x5A:
print("REG[%d] ^= REG[%d]" % (vm[idx+1], vm[idx+2]))
print("REG[%d] &= 0xFFFFFFFF" %(vm[idx+1]))
idx += 2
elif op == 0x50:
print("REG[%d] |= REG[%d]" % (vm[idx+1], vm[idx+2]))
print("REG[%d] &= 0xFFFFFFFF" %(vm[idx+1]))
idx += 2
elif op == 0xCC:
break
idx += 1
어떤 연산을 하는지 보여주는 스크립트를 짠다는게 이런식으로 짠다는 말이다. 각 기능들이 하는 연산들을 분석한 후에 python으로 그대로 옮겨줘서 기능이 실행될 때마다 어떤 연산이 실행된건지 print로 출력해서 보여주는 스크립트이다.
각 기능 밑에 0xffffffff를 and연산하는것도 같이 출력하는 이유는 python에서는 변수에 자료형이 없기 때문에 4바이트 자료형의 경우에는 저런식으로 and연산을 해서 변수 타입의 크기만큼 잘라줘야 한다.
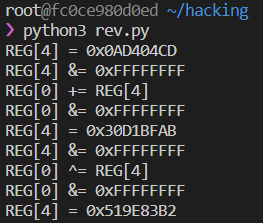
저 스크립트를 실행하면 이렇게 vm에서 어떤 연산이 수행되는지 굉장히 직관적으로 나오게 된다. 이제 출력된 결과물을 분석해서 연산을 어떤식으로 역산을 짜줄까에 대한 고민만 하면 된다. 7번째 인덱스가 0이어야 하니까 전형적인 방정식이고 z3솔버에 넣으면 나올만한 연산이었다.
from z3 import *
from pwn import *
FLAG = [BitVec('a%i'%i, 32) for i in range(4)]
REG = [x for x in FLAG]+[0]*4
s = Solver()
REG[4] = 0x0AD404CD
REG[4] &= 0xFFFFFFFF
REG[0] += REG[4]
REG[0] &= 0xFFFFFFFF
REG[4] = 0x30D1BFAB
REG[4] &= 0xFFFFFFFF
REG[0] ^= REG[4]
REG[0] &= 0xFFFFFFFF
REG[4] = 0x519E83B2
REG[4] &= 0xFFFFFFFF
REG[0] ^= REG[4]
REG[0] &= 0xFFFFFFFF
REG[5] = 0x4F7C80BB
REG[5] &= 0xFFFFFFFF
REG[1] ^= REG[5]
REG[1] &= 0xFFFFFFFF
REG[5] = 0x760D1C63
REG[5] &= 0xFFFFFFFF
REG[1] -= REG[5]
REG[1] &= 0xFFFFFFFF
REG[5] = 0x9431C393
REG[5] &= 0xFFFFFFFF
REG[1] ^= REG[5]
REG[1] &= 0xFFFFFFFF
REG[6] = 0xE8B9B2FB
REG[6] &= 0xFFFFFFFF
REG[2] -= REG[6]
REG[2] &= 0xFFFFFFFF
REG[6] = 0x9A71D729
REG[6] &= 0xFFFFFFFF
REG[2] += REG[6]
REG[2] &= 0xFFFFFFFF
REG[6] = 0x00066D75
REG[6] &= 0xFFFFFFFF
REG[2] ^= REG[6]
REG[2] &= 0xFFFFFFFF
REG[7] = 0x3E6EA272
REG[7] &= 0xFFFFFFFF
REG[3] ^= REG[7]
REG[3] &= 0xFFFFFFFF
REG[7] = 0xD411AC74
REG[7] &= 0xFFFFFFFF
REG[3] ^= REG[7]
REG[3] &= 0xFFFFFFFF
REG[7] = 0x975E5C43
REG[7] &= 0xFFFFFFFF
REG[3] ^= REG[7]
REG[3] &= 0xFFFFFFFF
REG[7] ^= REG[7]
REG[7] &= 0xFFFFFFFF
REG[7] |= REG[0]
REG[7] &= 0xFFFFFFFF
REG[7] |= REG[1]
REG[7] &= 0xFFFFFFFF
REG[7] |= REG[2]
REG[7] &= 0xFFFFFFFF
REG[7] |= REG[3]
REG[7] &= 0xFFFFFFFF
s.add(REG[7] == 0)
if s.check() == sat:
res = s.model()
for i in FLAG:
print(p32(int(str(res[i]))).decode(), end='')
그래서 이렇게 z3솔버에 그대로 넣어줬다. 여기서 주의할게 있는데 z3를 사용할때 단순히 미지수에 연산만 수행하고 값을 비교하는 방정식의 경우에는
from z3 import *
a = [BitVec("a%i"%i, 32) for i in range(2)]
s = Solver()
s.add(a[0]*5 == 4)
s.add(a[1]+8 == 2)
if s.check() == sat:
res = s.model()
print(res[a[0]])
이런 식으로 결과 배열에 미지수 배열의 요소로 접근이 가능했지만 이 문제에서는 REG[0] ^= REG[4] 이런식으로 미지수의 값이 직접적으로 바뀌기 때문에 저런식으로 접근하면 에러가 나게 된다. 따라서
FLAG = [BitVec('a%i'%i, 32) for i in range(4)]
REG = [x for x in FLAG]+[0]*4
이런 식으로 BitVec배열을 만들고 그걸 복사한 배열을 하나 더 만든다. 그리고 실질적인 연산은 복사본에서 수행하면 원본에는 영향을 미치지 않기 때문에 원래처럼 접근할 수 있게 된다. 이 문제는 동아리 수업시간에 풀어본 문제인데 첫 vm인 만큼 솔버에 어떤식으로 넣어야 할까 헷갈려서 삽질하기도 했지만 방정식 해 뽑아내고 마지막에 값 출력하는거에서 이걸 몰라서 하나하나 노가다로 플래그로 바꿔줬었다.
아무튼 아까 위에 올려둔 z3 solver에 때려박은 스크립트 실행하면
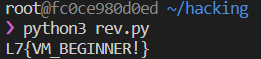
잘 나온다. 수업시간에 푼 기초 문제인 만큼 매우 간단하고 쉽다.
prob-1
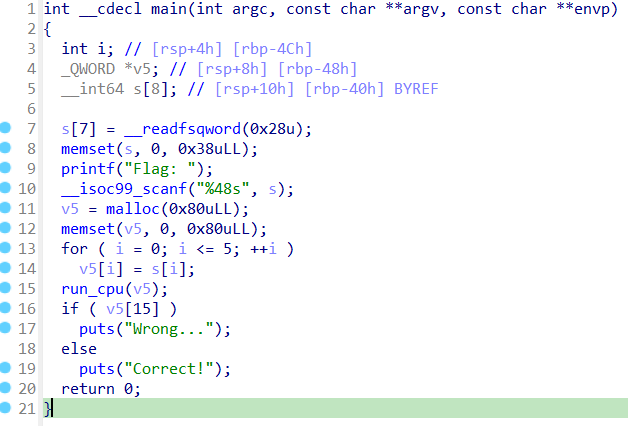
이 문제는 과제로 나온 문제라 혼자 푼 문제이다. 수업시간에 vm푸는법 처음 배울때는 삽질좀 했는데 이제는 감이 와서 30분안에 금방 했다. main의 큰 틀은 앞의 문제와 크게 다르지 않다. 값 입력받고 복사해서 run_cpu함수로 넘겨주고 연산 결과의 15번째 인덱스가 0이 되어야 한다.
__int64 __fastcall run_cpu(__int64 a1)
{
int v1; // eax
__int64 result; // rax
int v3; // eax
int v4; // eax
int v5; // eax
int v6; // eax
int v7; // eax
int v8; // eax
int v9; // [rsp+14h] [rbp-4h]
int v10; // [rsp+14h] [rbp-4h]
int v11; // [rsp+14h] [rbp-4h]
int v12; // [rsp+14h] [rbp-4h]
int v13; // [rsp+14h] [rbp-4h]
int v14; // [rsp+14h] [rbp-4h]
int v15; // [rsp+14h] [rbp-4h]
int v16; // [rsp+14h] [rbp-4h]
v9 = 0;
while ( 1 )
{
v1 = v9;
v10 = v9 + 1;
result = stub[v1];
if ( (_BYTE)result == 0xCC )
break;
switch ( (_BYTE)result )
{
case 0xBA:
v3 = v10;
v11 = v10 + 1;
result = stub[v3];
if ( (_BYTE)result )
{
if ( (_BYTE)result == 1 )
{
*(_QWORD *)(a1 + 8LL * stub[v11]) = *(unsigned int *)&stub[v11 + 1];
v9 = v11 + 5;
}
else
{
if ( (_BYTE)result != 2 )
return result;
*(_QWORD *)(a1 + 8LL * stub[v11]) = *(_QWORD *)&stub[v11 + 1];
v9 = v11 + 9;
}
}
else
{
*(_QWORD *)(a1 + 8LL * stub[v11]) = *(_QWORD *)(a1 + 8LL * stub[v11 + 1]);
v9 = v11 + 2;
}
break;
case 0x76:
v4 = v10;
v12 = v10 + 1;
result = stub[v4];
if ( (_BYTE)result )
{
if ( (_BYTE)result == 1 )
{
*(_QWORD *)(a1 + 8LL * stub[v12]) += *(unsigned int *)&stub[v12 + 1];
v9 = v12 + 5;
}
else
{
if ( (_BYTE)result != 2 )
return result;
*(_QWORD *)(a1 + 8LL * stub[v12]) += *(_QWORD *)&stub[v12 + 1];
v9 = v12 + 9;
}
}
else
{
*(_QWORD *)(a1 + 8LL * stub[v12]) += *(_QWORD *)(a1 + 8LL * stub[v12 + 1]);
v9 = v12 + 2;
}
break;
case 0x90:
v5 = v10;
v13 = v10 + 1;
result = stub[v5];
if ( (_BYTE)result )
{
if ( (_BYTE)result == 1 )
{
*(_QWORD *)(a1 + 8LL * stub[v13]) -= *(unsigned int *)&stub[v13 + 1];
v9 = v13 + 5;
}
else
{
if ( (_BYTE)result != 2 )
return result;
*(_QWORD *)(a1 + 8LL * stub[v13]) -= *(_QWORD *)&stub[v13 + 1];
v9 = v13 + 9;
}
}
else
{
*(_QWORD *)(a1 + 8LL * stub[v13]) -= *(_QWORD *)(a1 + 8LL * stub[v13 + 1]);
v9 = v13 + 2;
}
break;
case 0x83:
v6 = v10;
v14 = v10 + 1;
result = stub[v6];
if ( (_BYTE)result )
{
if ( (_BYTE)result == 1 )
{
*(_QWORD *)(a1 + 8LL * stub[v14]) &= *(unsigned int *)&stub[v14 + 1];
v9 = v14 + 5;
}
else
{
if ( (_BYTE)result != 2 )
return result;
*(_QWORD *)(a1 + 8LL * stub[v14]) &= *(_QWORD *)&stub[v14 + 1];
v9 = v14 + 9;
}
}
else
{
*(_QWORD *)(a1 + 8LL * stub[v14]) &= *(_QWORD *)(a1 + 8LL * stub[v14 + 1]);
v9 = v14 + 2;
}
break;
case 0x91:
v7 = v10;
v15 = v10 + 1;
result = stub[v7];
if ( (_BYTE)result )
{
if ( (_BYTE)result == 1 )
{
*(_QWORD *)(a1 + 8LL * stub[v15]) |= *(unsigned int *)&stub[v15 + 1];
v9 = v15 + 5;
}
else
{
if ( (_BYTE)result != 2 )
return result;
*(_QWORD *)(a1 + 8LL * stub[v15]) |= *(_QWORD *)&stub[v15 + 1];
v9 = v15 + 9;
}
}
else
{
*(_QWORD *)(a1 + 8LL * stub[v15]) |= *(_QWORD *)(a1 + 8LL * stub[v15 + 1]);
v9 = v15 + 2;
}
break;
case 0xEF:
*(_QWORD *)(a1 + 8LL * stub[v10]) = ~*(_QWORD *)(a1 + 8LL * stub[v10]);
v9 = v10 + 1;
break;
case 0x2E:
v8 = v10;
v16 = v10 + 1;
result = stub[v8];
if ( (_BYTE)result )
{
if ( (_BYTE)result == 1 )
{
*(_QWORD *)(a1 + 8LL * stub[v16]) ^= *(unsigned int *)&stub[v16 + 1];
v9 = v16 + 5;
}
else
{
if ( (_BYTE)result != 2 )
return result;
*(_QWORD *)(a1 + 8LL * stub[v16]) ^= *(_QWORD *)&stub[v16 + 1];
v9 = v16 + 9;
}
}
else
{
*(_QWORD *)(a1 + 8LL * stub[v16]) ^= *(_QWORD *)(a1 + 8LL * stub[v16 + 1]);
v9 = v16 + 2;
}
break;
default:
return result;
}
}
return result;
}
이번에는 vm코드가 꽤 길다. 선린 오기 전까지만 해도 IDA디컴파일 결과 1도 안건드리고 포인터 연산 깡으로 분석하고 그랬는데 이제는 조금씩 바꾸면서 분석하고 있다. 그래도 구조체 만드는건 귀찮기도 하고 복잡한 구조 아니면 굳이 안만들어도 분석에 크게 어려움이 없어서 구조체는 웬만해선 안만들고 있다.
__int64 __fastcall run_cpu(__int64 *a1)
{
int v1; // eax
__int64 opcode; // rax
int v3; // eax
int v4; // eax
int v5; // eax
int v6; // eax
int v7; // eax
int v8; // eax
int v9; // [rsp+14h] [rbp-4h]
int v10; // [rsp+14h] [rbp-4h]
int v11; // [rsp+14h] [rbp-4h]
int v12; // [rsp+14h] [rbp-4h]
int v13; // [rsp+14h] [rbp-4h]
int v14; // [rsp+14h] [rbp-4h]
int v15; // [rsp+14h] [rbp-4h]
int v16; // [rsp+14h] [rbp-4h]
v9 = 0;
while ( 1 )
{
v1 = v9;
v10 = v9 + 1;
opcode = stub[v1];
if ( (_BYTE)opcode == 0xCC )
break;
switch ( (_BYTE)opcode )
{
case 0xBA:
v3 = v10;
v11 = v10 + 1;
opcode = stub[v3];
if ( (_BYTE)opcode )
{
if ( (_BYTE)opcode == 1 )
{
a1[stub[v11]] = *(unsigned int *)&stub[v11 + 1];
v9 = v11 + 5;
}
else
{
if ( (_BYTE)opcode != 2 )
return opcode;
a1[stub[v11]] = *(_QWORD *)&stub[v11 + 1];
v9 = v11 + 9;
}
}
else
{
a1[stub[v11]] = a1[stub[v11 + 1]];
v9 = v11 + 2;
}
break;
case 0x76:
v4 = v10;
v12 = v10 + 1;
opcode = stub[v4];
if ( (_BYTE)opcode )
{
if ( (_BYTE)opcode == 1 )
{
a1[stub[v12]] += *(unsigned int *)&stub[v12 + 1];
v9 = v12 + 5;
}
else
{
if ( (_BYTE)opcode != 2 )
return opcode;
a1[stub[v12]] += *(_QWORD *)&stub[v12 + 1];
v9 = v12 + 9;
}
}
else
{
a1[stub[v12]] += a1[stub[v12 + 1]];
v9 = v12 + 2;
}
break;
case 0x90:
v5 = v10;
v13 = v10 + 1;
opcode = stub[v5];
if ( (_BYTE)opcode )
{
if ( (_BYTE)opcode == 1 )
{
a1[stub[v13]] -= *(unsigned int *)&stub[v13 + 1];
v9 = v13 + 5;
}
else
{
if ( (_BYTE)opcode != 2 )
return opcode;
a1[stub[v13]] -= *(_QWORD *)&stub[v13 + 1];
v9 = v13 + 9;
}
}
else
{
a1[stub[v13]] -= a1[stub[v13 + 1]];
v9 = v13 + 2;
}
break;
case 0x83:
v6 = v10;
v14 = v10 + 1;
opcode = stub[v6];
if ( (_BYTE)opcode )
{
if ( (_BYTE)opcode == 1 )
{
a1[stub[v14]] = *(unsigned int *)&stub[v14 + 1] & (unsigned __int64)a1[stub[v14]];
v9 = v14 + 5;
}
else
{
if ( (_BYTE)opcode != 2 )
return opcode;
a1[stub[v14]] &= *(_QWORD *)&stub[v14 + 1];
v9 = v14 + 9;
}
}
else
{
a1[stub[v14]] &= a1[stub[v14 + 1]];
v9 = v14 + 2;
}
break;
case 0x91:
v7 = v10;
v15 = v10 + 1;
opcode = stub[v7];
if ( (_BYTE)opcode )
{
if ( (_BYTE)opcode == 1 )
{
a1[stub[v15]] = *(unsigned int *)&stub[v15 + 1] | (unsigned __int64)a1[stub[v15]];
v9 = v15 + 5;
}
else
{
if ( (_BYTE)opcode != 2 )
return opcode;
a1[stub[v15]] |= *(_QWORD *)&stub[v15 + 1];
v9 = v15 + 9;
}
}
else
{
a1[stub[v15]] |= a1[stub[v15 + 1]];
v9 = v15 + 2;
}
break;
case 0xEF:
a1[stub[v10]] = ~a1[stub[v10]];
v9 = v10 + 1;
break;
case 0x2E:
v8 = v10;
v16 = v10 + 1;
opcode = stub[v8];
if ( (_BYTE)opcode )
{
if ( (_BYTE)opcode == 1 )
{
a1[stub[v16]] = *(unsigned int *)&stub[v16 + 1] ^ (unsigned __int64)a1[stub[v16]];
v9 = v16 + 5;
}
else
{
if ( (_BYTE)opcode != 2 )
return opcode;
a1[stub[v16]] ^= *(_QWORD *)&stub[v16 + 1];
v9 = v16 + 9;
}
}
else
{
a1[stub[v16]] ^= a1[stub[v16 + 1]];
v9 = v16 + 2;
}
break;
default:
return opcode;
}
}
return opcode;
}
이렇게 바꿔줄 수 있다. 코드 양에 쫄 수도 있지만 기능은 간단하다. 그냥 한번에 opcode를 2개 가지고 연산을 하고 첫번째 opcode는 vm의 기능, 2번째 opcode는 연산할 피연산자의 크기를 뜻한다.
이것도 마찬가지로 vm의 연산을 직관적으로 뽑아오는 스크립트를 짜줘야 한다.
vm = [0x2E, 0x02, 0x00, 0x5E, 0xCC, 0xEA, 0x30, 0x26, 0x1B, 0xA0, 0x89, 0x76, 0x02, 0x00, 0x44, 0xDC, 0xF6, 0x05, 0x40, 0xA2, 0x41, 0xF2, 0x2E, 0x02, 0x00, 0xE9, 0xA5, 0x55, 0x6C, 0x5D, 0x94, 0x54, 0xE7, 0xEF, 0x00, 0x2E, 0x02, 0x00, 0xB1, 0xA5, 0xEE, 0x14, 0xE4, 0x5A, 0x46, 0xBB, 0x76, 0x02, 0x00, 0x11, 0xD4, 0xE9, 0x0D, 0xAD, 0x51, 0xC5, 0x93, 0xEF, 0x00, 0x90, 0x02, 0x00, 0xFD, 0x02, 0x4A, 0xF4, 0x62, 0xD6, 0x5E, 0x01, 0x2E, 0x02, 0x01, 0x84, 0x6F, 0x8C, 0xF9, 0x0E, 0xC4, 0x4A, 0xCF, 0x76, 0x02, 0x01, 0x9B, 0xB5, 0xE5, 0x8C, 0xAA, 0xD9, 0x4A, 0x58, 0x2E, 0x02, 0x01, 0x0A, 0x9D, 0xF0, 0x60, 0x76, 0x00, 0x73, 0x23, 0xEF, 0x01, 0x2E, 0x02, 0x01, 0x75, 0x27, 0xEC, 0x1B, 0x4E, 0x9D, 0x07, 0x97, 0x76, 0x02, 0x01, 0xF4, 0xE0, 0xA2, 0x83, 0xD6, 0xBF, 0x63, 0xD2, 0xEF, 0x01, 0x90, 0x02, 0x01, 0x24, 0x7D, 0x00, 0xAF, 0xED, 0x38, 0xCB, 0x88, 0x2E, 0x02, 0x02, 0x6B, 0xB6, 0x75, 0xCE, 0x4B, 0xCE, 0xEA, 0xD4, 0x76, 0x02, 0x02, 0x54, 0xE8, 0x89, 0xAF, 0xEE, 0x61, 0x99, 0xD4, 0x2E, 0x02, 0x02, 0xA8, 0x85, 0x51, 0x18, 0x3D, 0x9F, 0x88, 0xC8, 0xEF, 0x02, 0x2E, 0x02, 0x02, 0xAB, 0x96, 0x1D, 0x6C, 0x9C, 0x46, 0xB7, 0xBC, 0x76, 0x02, 0x02, 0xB1, 0x8F, 0x1A, 0x1F, 0xB8, 0x50, 0xCA, 0x71, 0xEF, 0x02, 0x90, 0x02, 0x02, 0xDD, 0x3C, 0xE0, 0x19, 0xEA, 0xE2, 0x36, 0xBD, 0x2E, 0x02, 0x03, 0xD4, 0xE8, 0xD8, 0x1F, 0xBA, 0x3F, 0x4C, 0x5B, 0x76, 0x02, 0x03, 0xA6, 0x6A, 0xA3, 0xD6, 0xE8, 0x3E, 0xCF, 0xEB, 0x2E, 0x02, 0x03, 0x4F, 0x0D, 0x75, 0xCE, 0xBD, 0x9F, 0x75, 0x03, 0xEF, 0x03, 0x2E, 0x02, 0x03, 0x3B, 0xF0, 0x03, 0x72, 0x37, 0xF9, 0xF1, 0x60, 0x76, 0x02, 0x03, 0xA2, 0x7C, 0xC1, 0x60, 0xAB, 0xE7, 0x63, 0x16, 0xEF, 0x03, 0x90, 0x02, 0x03, 0xA3, 0x57, 0x82, 0x37, 0xB2, 0xE7, 0xF4, 0x4A, 0x2E, 0x02, 0x04, 0x8F, 0xE5, 0x0F, 0xF2, 0x7E, 0x5E, 0xD3, 0x23, 0x76, 0x02, 0x04, 0x77, 0xA5, 0x07, 0x6F, 0xA4, 0x7E, 0x6C, 0xD6, 0x2E, 0x02, 0x04, 0xB0, 0xED, 0x3E, 0x38, 0xC3, 0x6A, 0x69, 0x8D, 0xEF, 0x04, 0x2E, 0x02, 0x04, 0x5B, 0x9E, 0x4A, 0xCB, 0x1D, 0xDE, 0xA9, 0xAD, 0x76, 0x02, 0x04, 0x77, 0xC4, 0xD0, 0x41, 0xB0, 0x03, 0x34, 0xED, 0xEF, 0x04, 0x90, 0x02, 0x04, 0x35, 0x79, 0x51, 0x91, 0x55, 0x1D, 0x95, 0x30, 0x2E, 0x02, 0x05, 0xD4, 0xB8, 0x1D, 0x54, 0x3E, 0x40, 0x71, 0x55, 0x76, 0x02, 0x05, 0x22, 0x2F, 0x06, 0x80, 0xBA, 0xD3, 0x1D, 0xAF, 0x2E, 0x02, 0x05, 0x17, 0xF0, 0x22, 0xD9, 0x74, 0x4B, 0x19, 0x55, 0xEF, 0x05, 0x2E, 0x02, 0x05, 0x07, 0x84, 0x1D, 0xB1, 0xBB, 0x1F, 0xF0, 0x92, 0x76, 0x02, 0x05, 0x4A, 0x0B, 0x34, 0xE7, 0x25, 0x30, 0x36, 0xDB, 0xEF, 0x05, 0x90, 0x02, 0x05, 0xD3, 0x75, 0xE8, 0xD4, 0x11, 0x17, 0x30, 0xE8, 0x91, 0x00, 0x0F, 0x00, 0x91, 0x00, 0x0F, 0x01, 0x91, 0x00, 0x0F, 0x02, 0x91, 0x00, 0x0F, 0x03, 0x91, 0x00, 0x0F, 0x04, 0x91, 0x00, 0x0F, 0x05, 0xCC]
idx = 0
while True:
v1 = idx
v10 = idx+1
op = vm[v1]
if op == 0xBA:
v3 = v10
v11 = v10+1
op = vm[v3]
if op:
if op == 1:
print("REG[%d] = 0x%08X" % (vm[v11], int.from_bytes(vm[v11+1:v11+1+4], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v11])
idx = v11 + 5
elif op == 2:
print("REG[%d] = 0x%08X" % (vm[v11], int.from_bytes(vm[v11+1:v11+1+8], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v11])
idx = v11 + 9
else:
print("REG[%d] = REG[%d]" % (vm[v11], vm[v11+1]))
idx = v11 + 2
elif op == 0x76:
v4 = v10
v12 = v10+1
op = vm[v4]
if op:
if op == 1:
print("REG[%d] += 0x%08X" % (vm[v12], int.from_bytes(vm[v12+1:v12+1+4], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v12])
idx = v12 + 5
elif op == 2:
print("REG[%d] += 0x%08X" % (vm[v12], int.from_bytes(vm[v12+1:v12+1+8], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v12])
idx = v12 + 9
else:
print("REG[%d] += REG[%d]" % (vm[v12], vm[v12+1]))
idx = v12 + 2
elif op == 0x90:
v5 = v10
v13 = v10+1
op = vm[v5]
if op:
if op == 1:
print("REG[%d] -= 0x%08X" % (vm[v13], int.from_bytes(vm[v13+1:v13+1+4], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v13])
idx = v13 + 5
elif op == 2:
print("REG[%d] -= 0x%08X" % (vm[v13], int.from_bytes(vm[v13+1:v13+1+8], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v13])
idx = v13 + 9
else:
print("REG[%d] -= REG[%d]" % (vm[v13], vm[v13+1]))
idx = v13 + 2
elif op == 0x83:
v6 = v10
v14 = v10+1
op = vm[v6]
if op:
if op == 1:
print("REG[%d] &= 0x%08X" % (vm[v14], int.from_bytes(vm[v14+1:v14+1+4], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v14])
idx = v14 + 5
elif op == 2:
print("REG[%d] &= 0x%08X" % (vm[v14], int.from_bytes(vm[v14+1:v14+1+8], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v14])
idx = v14 + 9
else:
print("REG[%d] &= REG[%d]" % (vm[v14], vm[v14+1]))
idx = v14 + 2
elif op == 0x91:
v7 = v10
v15 = v10+1
op = vm[v7]
if op:
if op == 1:
print("REG[%d] |= 0x%08X" % (vm[v15], int.from_bytes(vm[v15+1:v15+1+4], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v15])
idx = v15 + 5
elif op == 2:
print("REG[%d] |= 0x%08X" % (vm[v15], int.from_bytes(vm[v15+1:v15+1+8], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v15])
idx = v15 + 9
else:
print("REG[%d] |= REG[%d]" % (vm[v15], vm[v15+1]))
idx = v15 + 2
elif op == 0xEF:
print("REG[%d] = ~REG[%d]" % (vm[v10], vm[v10]))
idx = v10+1
elif op == 0x2E:
v8 = v10
v16 = v10+1
op = vm[v8]
if op:
if op == 1:
print("REG[%d] ^= 0x%08X" % (vm[v16], int.from_bytes(vm[v16+1:v16+1+4], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v16])
idx = v16 + 5
elif op == 2:
print("REG[%d] ^= 0x%08X" % (vm[v16], int.from_bytes(vm[v16+1:v16+1+8], "little")))
print("REG[%d] &= 0xFFFFFFFFFFFFFFFF" % vm[v16])
idx = v16 + 9
else:
print("REG[%d] ^= REG[%d]" % (vm[v16], vm[v16+1]))
idx = v16 + 2
else:
break
코드가 좀 길긴 한데 별거 없다. 그냥 vm기능 그대로 옮겨서 어떤 연산 했는지 출력해주는 스크립트이다.
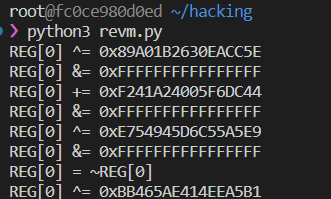
실행하면 잘 나온다. 이것도 z3느낌 나서 한번 z3에 그대로 넣어봤다.
from z3 import *
from pwn import *
FLAG = [BitVec('a%i'%i, 64) for i in range(6)]
REG = [x for x in FLAG]+[0]*10
s = Solver()
REG[0] ^= 0x89A01B2630EACC5E
REG[0] &= 0xFFFFFFFFFFFFFFFF
REG[0] += 0xF241A24005F6DC44
REG[0] &= 0xFFFFFFFFFFFFFFFF
REG[0] ^= 0xE754945D6C55A5E9
REG[0] &= 0xFFFFFFFFFFFFFFFF
REG[0] = ~REG[0]
REG[0] ^= 0xBB465AE414EEA5B1
REG[0] &= 0xFFFFFFFFFFFFFFFF
REG[0] += 0x93C551AD0DE9D411
REG[0] &= 0xFFFFFFFFFFFFFFFF
REG[0] = ~REG[0]
REG[0] -= 0x15ED662F44A02FD
REG[0] &= 0xFFFFFFFFFFFFFFFF
REG[1] ^= 0xCF4AC40EF98C6F84
REG[1] &= 0xFFFFFFFFFFFFFFFF
REG[1] += 0x584AD9AA8CE5B59B
REG[1] &= 0xFFFFFFFFFFFFFFFF
REG[1] ^= 0x2373007660F09D0A
REG[1] &= 0xFFFFFFFFFFFFFFFF
REG[1] = ~REG[1]
REG[1] ^= 0x97079D4E1BEC2775
REG[1] &= 0xFFFFFFFFFFFFFFFF
REG[1] += 0xD263BFD683A2E0F4
REG[1] &= 0xFFFFFFFFFFFFFFFF
REG[1] = ~REG[1]
REG[1] -= 0x88CB38EDAF007D24
REG[1] &= 0xFFFFFFFFFFFFFFFF
REG[2] ^= 0xD4EACE4BCE75B66B
REG[2] &= 0xFFFFFFFFFFFFFFFF
REG[2] += 0xD49961EEAF89E854
REG[2] &= 0xFFFFFFFFFFFFFFFF
REG[2] ^= 0xC8889F3D185185A8
REG[2] &= 0xFFFFFFFFFFFFFFFF
REG[2] = ~REG[2]
REG[2] ^= 0xBCB7469C6C1D96AB
REG[2] &= 0xFFFFFFFFFFFFFFFF
REG[2] += 0x71CA50B81F1A8FB1
REG[2] &= 0xFFFFFFFFFFFFFFFF
REG[2] = ~REG[2]
REG[2] -= 0xBD36E2EA19E03CDD
REG[2] &= 0xFFFFFFFFFFFFFFFF
REG[3] ^= 0x5B4C3FBA1FD8E8D4
REG[3] &= 0xFFFFFFFFFFFFFFFF
REG[3] += 0xEBCF3EE8D6A36AA6
REG[3] &= 0xFFFFFFFFFFFFFFFF
REG[3] ^= 0x3759FBDCE750D4F
REG[3] &= 0xFFFFFFFFFFFFFFFF
REG[3] = ~REG[3]
REG[3] ^= 0x60F1F9377203F03B
REG[3] &= 0xFFFFFFFFFFFFFFFF
REG[3] += 0x1663E7AB60C17CA2
REG[3] &= 0xFFFFFFFFFFFFFFFF
REG[3] = ~REG[3]
REG[3] -= 0x4AF4E7B2378257A3
REG[3] &= 0xFFFFFFFFFFFFFFFF
REG[4] ^= 0x23D35E7EF20FE58F
REG[4] &= 0xFFFFFFFFFFFFFFFF
REG[4] += 0xD66C7EA46F07A577
REG[4] &= 0xFFFFFFFFFFFFFFFF
REG[4] ^= 0x8D696AC3383EEDB0
REG[4] &= 0xFFFFFFFFFFFFFFFF
REG[4] = ~REG[4]
REG[4] ^= 0xADA9DE1DCB4A9E5B
REG[4] &= 0xFFFFFFFFFFFFFFFF
REG[4] += 0xED3403B041D0C477
REG[4] &= 0xFFFFFFFFFFFFFFFF
REG[4] = ~REG[4]
REG[4] -= 0x30951D5591517935
REG[4] &= 0xFFFFFFFFFFFFFFFF
REG[5] ^= 0x5571403E541DB8D4
REG[5] &= 0xFFFFFFFFFFFFFFFF
REG[5] += 0xAF1DD3BA80062F22
REG[5] &= 0xFFFFFFFFFFFFFFFF
REG[5] ^= 0x55194B74D922F017
REG[5] &= 0xFFFFFFFFFFFFFFFF
REG[5] = ~REG[5]
REG[5] ^= 0x92F01FBBB11D8407
REG[5] &= 0xFFFFFFFFFFFFFFFF
REG[5] += 0xDB363025E7340B4A
REG[5] &= 0xFFFFFFFFFFFFFFFF
REG[5] = ~REG[5]
REG[5] -= 0xE8301711D4E875D3
REG[5] &= 0xFFFFFFFFFFFFFFFF
REG[15] |= REG[0]
REG[15] |= REG[1]
REG[15] |= REG[2]
REG[15] |= REG[3]
REG[15] |= REG[4]
REG[15] |= REG[5]
s.add(REG[15] == 0)
if s.check() == sat:
res = s.model()
for i in FLAG:
print(p64(int(str(res[i]))).decode(), end='')
이렇게 z3에 그대로 던져주면

플래그가 나온다.
개인적으로 이번 수업은 Layer7에 들어와서 가장 열심히 들었던 수업이 아닐까 싶다. 대부분 아는 내용이라서 수업을 그렇게 열심히 듣지는 않았었는데 이번 내용은 개인적으로 궁금하기도 했고 한번 배워보고 싶은 내용이었어서 엄청 열심히 들었던것 같다. 덕분에 이제 리버싱 vm문제를 보고도 쫄지 않고 도전해볼만한 자신감이 생겼다. 수업해주신 서준님 감사합니다.
'Layer7' 카테고리의 다른 글
| Layer7 - 포너블 1차시 수업 (0) | 2022.10.04 |
|---|---|
| Layer7 - 리버싱 11차시 과제 (0) | 2022.10.04 |
| Layer7 - 리버싱 9차시 과제 (0) | 2022.10.04 |
| Layer7 - 리버싱 8차시 과제 rev-basic-8 (0) | 2022.10.04 |
| Layer7 - 리버싱 8차시 과제 rev-basic-7 (0) | 2022.10.04 |


